'deepseek学习笔记'
Deepseek学习笔记
记录目的
为了记录自己每日的学习成功,检验自己的输入效果,觉得对每日的学习内容进行记录。
强化学习
我第一次在大模型领域听到强化学习这个词,先对强化学习有个大概的认知
强化学习概述
基本概念
强化学习有5个基本概念:
- agent
- state
- environment
- action
- reward
agent会根据当前environment的state做出相应的action,已到达总的reward最大

agent并不会每次都采取概率最大的action,因为agent期望能够探索更高分数的可能
强化学习 vs 监督学习
- 强化学习的样本是基于时间的序列,具有强相关性,而监督学习其数据往往是独立同分布的
- 强化学习的纠错不及时,即延时奖励,环境只会告诉智能体这个动作是错误的,但没有告诉正确的动作是什么,而监督学习会给出正确的标签,并且立马纠错
- 强化学习的上限更高,监督学习的数据是人类标注的,其上限就是人类的表现
智能体的组成部分
策略
智能体会用策略来采取下一步的动作,策略是将输入状态转化为相应动作的一个函数
- 随机性策略:输出所有动作的概率,并基于该概率分布进行采样
- 确定性策略:每次都选择概率最大的动作
通常采取随机性策略:利于探索环境,并且智能体的动作不容易对手被预测
价值函数
价值函数的值是对未来奖励的预测
Actor
目标:训练一个神经网络,使得其在所有可能的状态动作序列中的回报期望最大
回报期望

实际情况,是用N次episode的回报(R)的平均值来近似R的期望
最大化R的期望
- 将R的期望的导函数进行变形

- 将对数求导部分进行展开
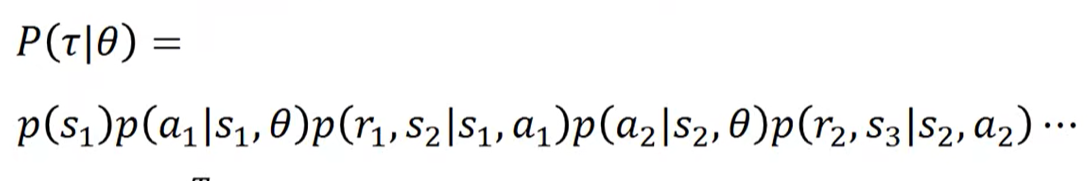
求导时不需要关注没有θ的部分
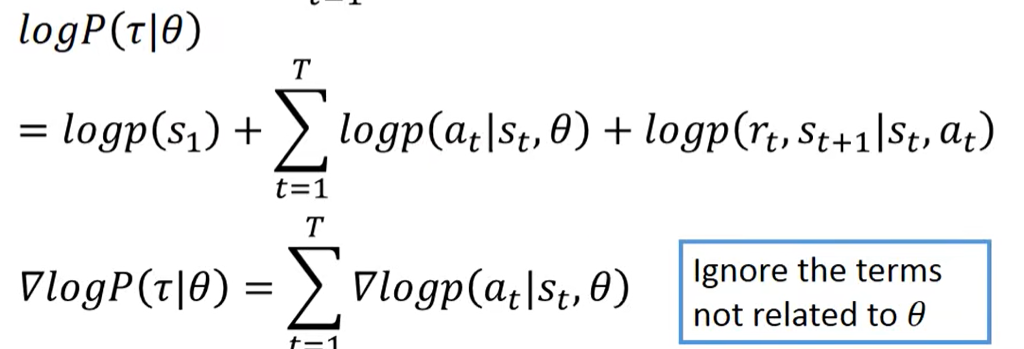
- 最终形式如下

- 采用回报R作为每个时间点概率对数的乘积而非该时间点获得的奖励r,是因为要考虑该动作对整局游戏的影响,而非当前时刻,否则,如果某个动作得到的r为正,则该actor就只会一直采取该动作,变成一个智障
- 采用对数概率是为了实现正则化
添加bias
为了防止采用过程中,较好的action的几率因为未被采样到而减小,让R减去一个baseline,使得R有正有负,这样较好的R其相关的action概率一定会增加,较差的R其相关的action概率一定会减小
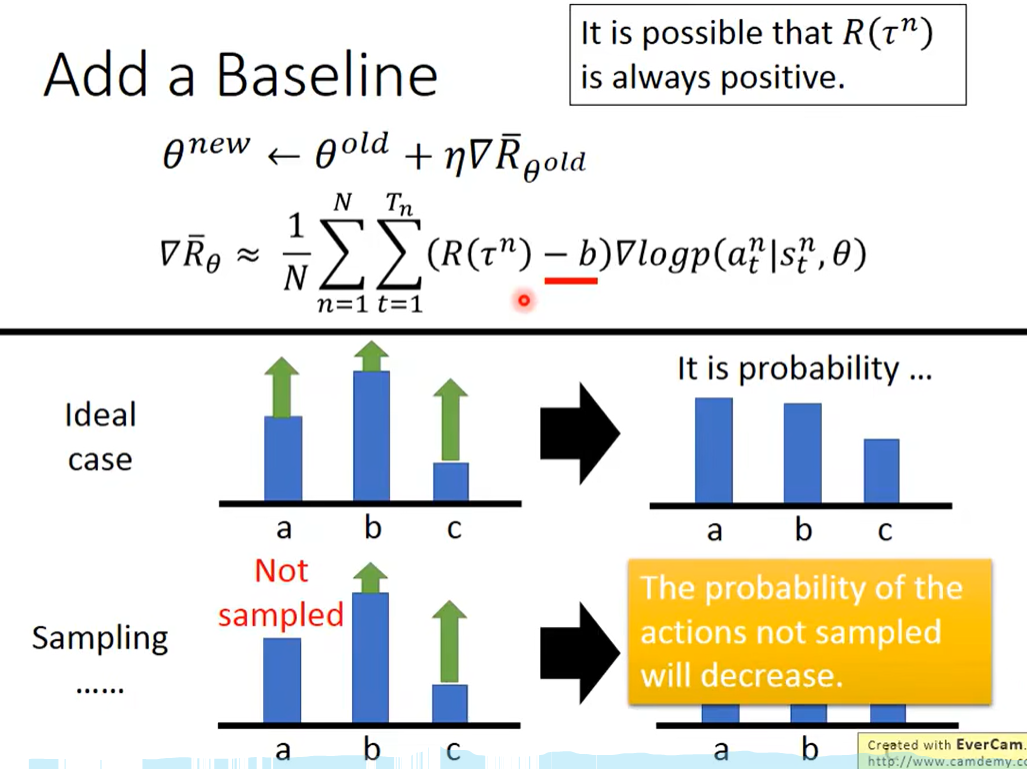
改变R-b
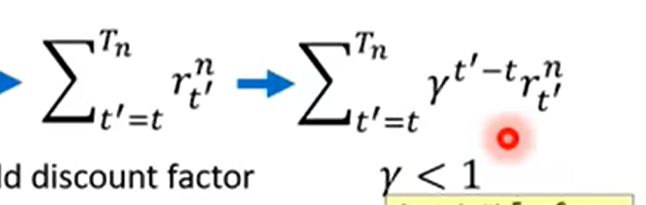
同一局游戏的每个动作的权重不应该是一样的,只计算该时间点之后的rewards
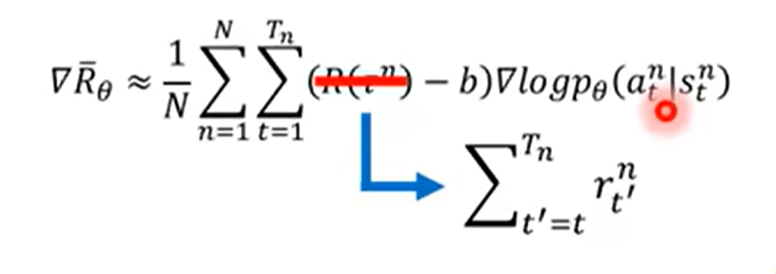
同时,计算的reward和应该是加权和,权重随时间步逐渐衰减
Critic
用于评判当前actor的好坏,具体表现为一个状态价值函数,输入为state,输出为该状态到游戏结束能够获得的reward总和
V函数:state之后的reward和

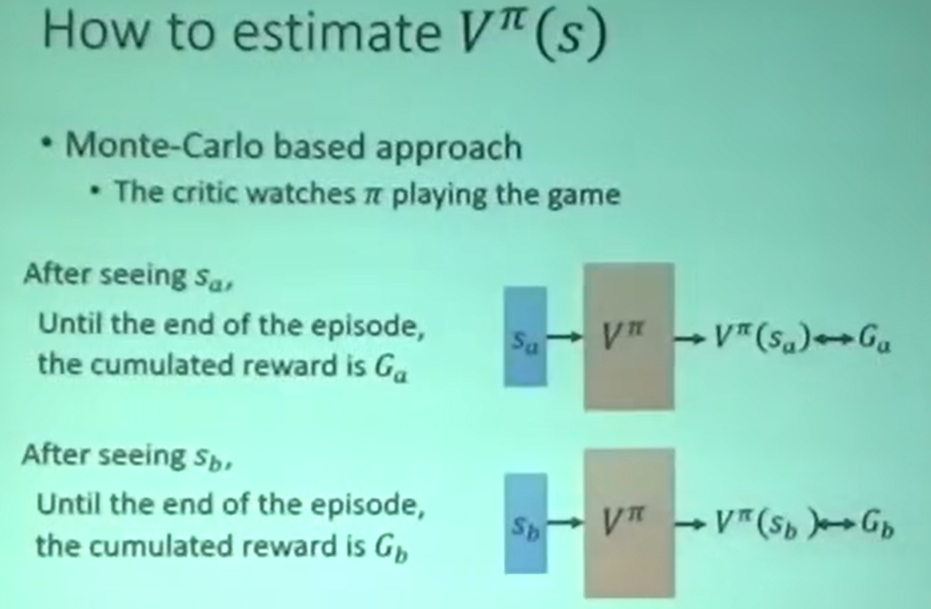
MC训练
玩完一句游戏后,让其输出值接近真实值
TD训练
让相邻状态输出的值的差值接近reward,可以在游戏进行中进行参数更新

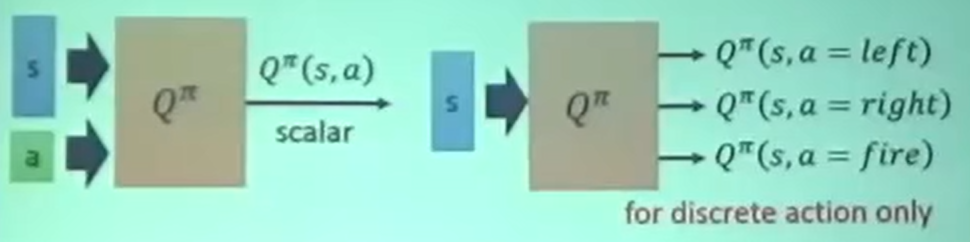
State-action value function
Q函数:(state, action)—> (rewards)
Q-learning:能够通过Q函数更新actor的表现
新actor的动作取决去旧actor能获得最大reward的动作
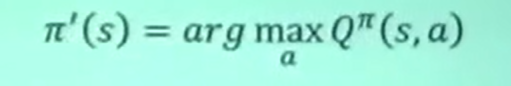
PPO
on-policy vs off-policy
- on-policy: 采样和训练的是一个actor
- off-policy: 采样和训练不是一个actor
当θ更新后,旧的采样数据不符合旧θ的产生的概率分布,所以不能用于继续用于训练,这导致训练效率较低。
如何让采样到的数据能够重复使用:
使用两个actor,一个用于采样,另一个用于训练。用于训练的actor可以多次使用采用actor一次采样的数据进行训练。

如何让两个不同概率分布产生联系:
假设现在要对p概率分布求期望,但是无法对p分布进行采样,而可以对另外一个q概率分布进行采样,那么通过表达式的变化,可以将对p概率分布求期望改写为对q概率分布求期望
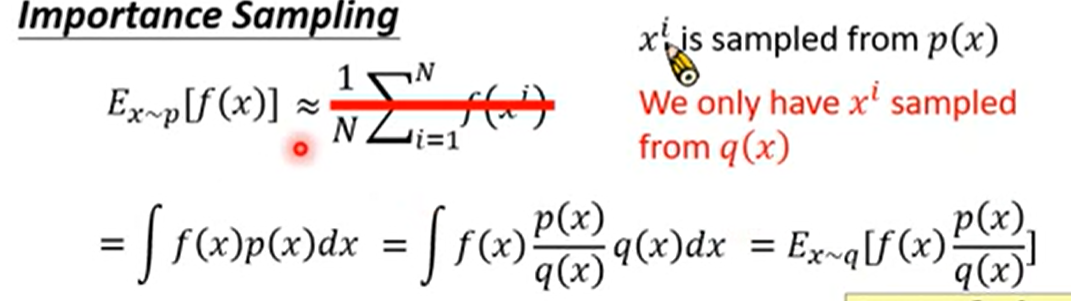
On-policy ----------> Off-policy

目标函数

加入KL散度项,避免两概率分布差异过大

动态调整β
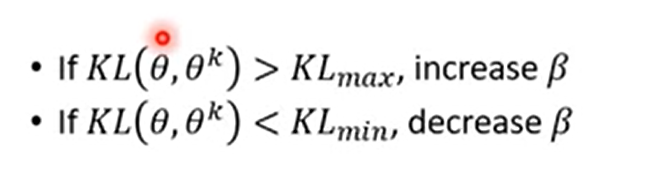
另一种形式的PPO
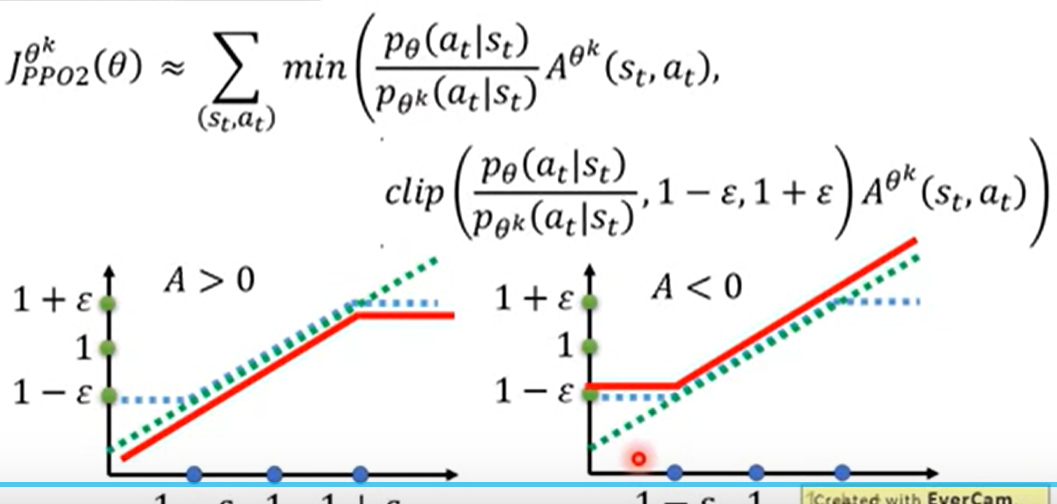
看过最通俗易懂的PPO讲解:拆解大语言模型RLHF中的PPO
总结如下:
- 两个LLM模型,二者结构上一致,只是参数不同,一个作为旧版本用于生成样本数据、旧的预期价值、旧的token概率,一个作为待更新版本,利用旧版本生成的样本,生成当前的预期价值、当前的token概率
- RM利用旧版本生成的token概率、基座模型生成的token概率计算每个token的reward,进一步利用旧的预期价值可以生成每个token的优势值
- 当前版本使用每个token的优势值,旧的token概率,当前的token概率,得出actor_loss,进行参数更新
GRPO
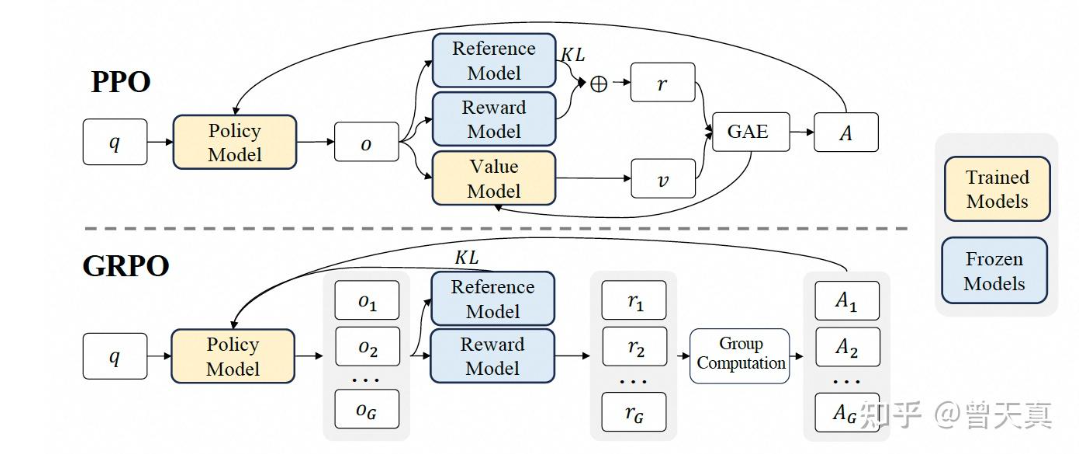
continue…>>>